 Marginal Lab
Marginal Lab
The Fallacy of Exhaustive Effort: Why Leaving No Stone Unturned Can Bury You
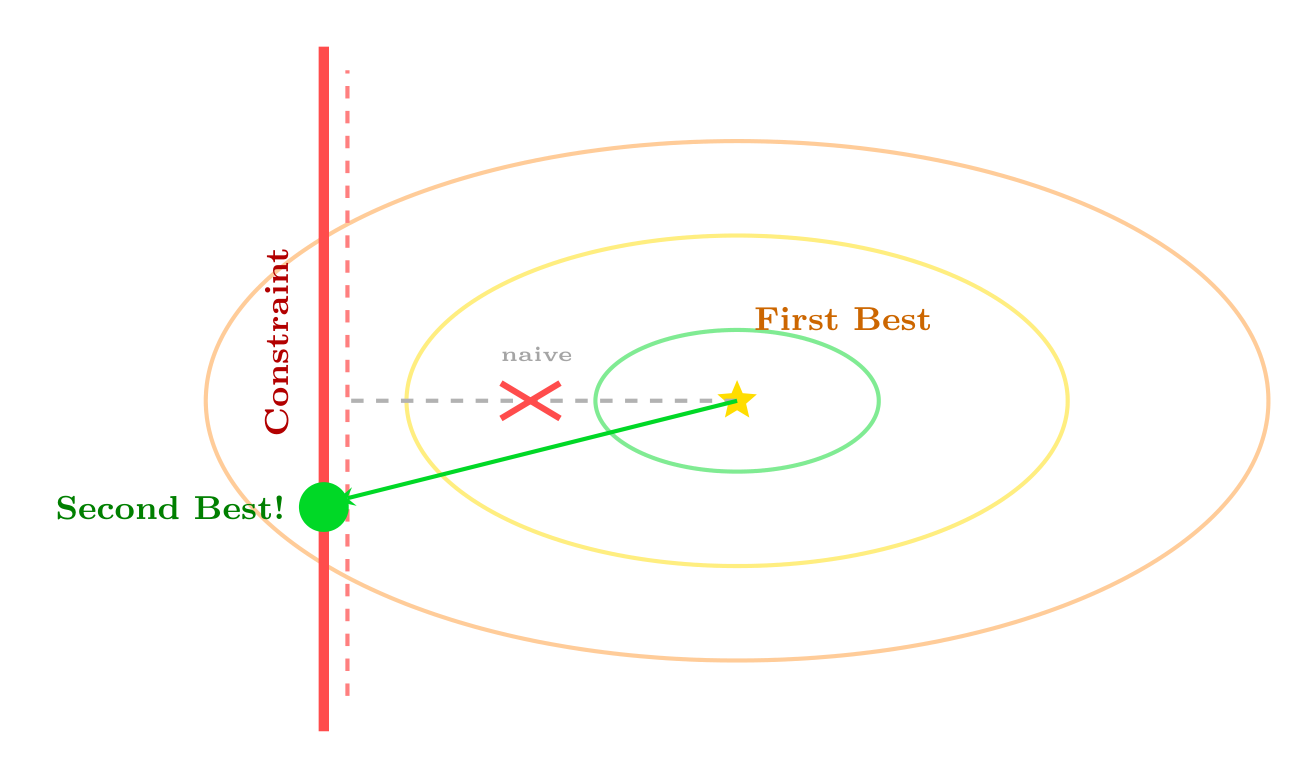
If satisfying all conditions for an optimal outcome is good, then satisfying as many as possible must be second best. This reasoning is false. When a constraint prevents one condition from being met, the remaining conditions are no longer individually desirable. Satisfying them can worsen the outcome. Drawing on the theory of the second best, we show that you should approach the problem in a different way.
Download PDFThe Prevailing Intuition
We always believe we should leave no stone unturned when we pursue our goals. That is, we should do as much as possible to close the gap between the current state and the target. When successful people give lectures, they talk about their “good” habits, like sleeping early, waking up early, reading books, and so on. We often treat those people as “landmarks” and those habits as criteria for success. Therefore, we are sold on the idea that we should follow them as much as we can to get close to success. More effort equals better outcome.
However, this argument is generally not true. In other words, it is not always preferable to do as much as we can.
The Formal Problem
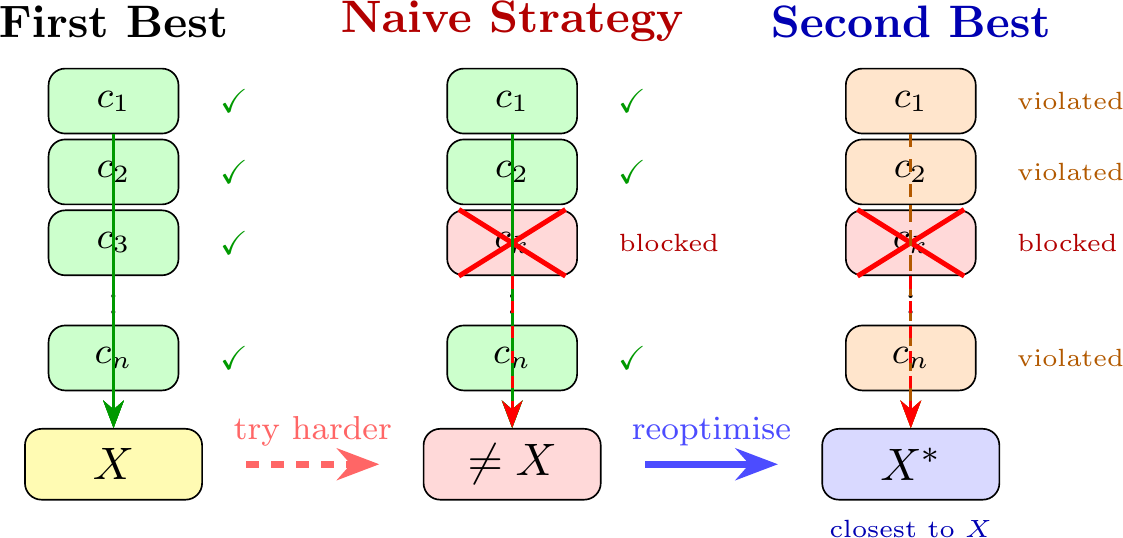
Formally, suppose there are $n$ conditions, $c_1, c_2, \dots, c_n$. Satisfying all of them would lead to a favourable outcome $X$. Now, given that at least one of the conditions $c_k$ cannot be satisfied, should we try our best to satisfy all other conditions? Does this strategy bring us closer to the favourable outcome?
 The second-best optimum $X^{\ast}$ may require violating the remaining conditions.
The second-best optimum $X^{\ast}$ may require violating the remaining conditions.
The answer is no. The concept is simple: the optimal strategy depends on your constraints. If you have no constraints, you can satisfy all $n$ conditions and get a favourable outcome. If you add some constraints to the problem, the objective does not change, but all of your optimal conditions are altered because they are often correlated. The optimal solution structure is completely different from the unconstrained problem.
The Dinner Party Metaphor
Imagine you go to a Michelin-starred restaurant. You want to see three things:
- Dim lighting.
- A big plate with small food.
- Nice food.
Now suppose that Condition (3) will not be satisfied. The food is terrible. Would you still want to satisfy Conditions 1 and 2? According to the “leave no stone unturned” logic, the answer is yes. You dim the lights romantically. You bring out the giant white plates and arrange the food with tweezers.
But what is the result? You have made it worse. The dim lighting looks like a deliberate attempt to hide the bad food. The large plate makes the small, bad food look even more pathetic by comparison. The whole thing becomes a parody of fine dining. In this scenario, the optimal move is to turn on the bright lights and just order pizza.
Of course, this is merely a metaphor to build intuition. Let us now examine some real examples in economics.
Monopoly and Pollution
Imagine a society with a monopoly firm that pollutes the river. First, we often say monopoly is bad. It is because a monopoly would produce less output than a competitive market and hence set a price higher than that of a competitive market. It inflicts a loss on the consumers. Second, we often say pollution is bad. It is because the firm does not need to pay for the social cost of the pollution, and hence produces more than the optimal amount. It inflicts a loss on society.
 Monopoly restricts output; pollution expands it.
Monopoly restricts output; pollution expands it.
The best policy to handle the problem is, of course, to break up the monopoly and charge a tax on pollution. However, if the monopoly cannot be broken up, or the pollution cannot be measured, what do we do? A piecemeal policy is to “do as much as we can.” But it is not optimal in this case.
Breaking up the monopoly increases its production scale and lowers the price, but it means higher pollution. Taxing the pollution means we lower its scale, and hence the price will be even higher. As you may see, the “bad” side of monopoly and the “bad” side of pollution offset each other naturally. The optimal policy could be “do nothing.”
Taxes and Public Goods
Imagine a society with two “good” conditions: low taxes are good (they let people keep what they earn and encourage work), and public goods are good (roads, courts, you need them). The first-best world satisfies both: the government funds public goods with a lump-sum tax that does not distort anyone’s incentives. Everyone works and everyone pays.
Now suppose a lump-sum tax is not possible. The government can only raise revenue through income taxes, which distort labour supply. Should we still try to fund public goods as much as we can, because public goods are good? The “leave no stone unturned” logic says yes: fund everything, tax everything, do as much as we can.
But this is not optimal. Every additional dollar of income tax discourages work further. At some point, the deadweight loss from taxation outweighs the benefit of the public good it funds. The “good” of public goods and the “good” of low taxes pull against each other. The optimal policy is to fund only those whose benefit exceeds the distortion they cause. Some “good” things must be left unfunded, because paying for them makes the overall outcome worse.
Flat Taxation and the Leisure Constraint
You might say: fine, income taxes distort. So let us switch to a flat general sales tax. One rate on everything, no exceptions. It sounds simple and it sounds fair. In a world where we could tax all goods, it would be optimal.
But here is the catch. A flat sales tax is only optimal if you can tax all goods at the same rate. And you cannot. Why? Because leisure cannot be taxed. When someone chooses to work fewer hours and enjoy more free time, the government gets nothing. A parent who stays home to raise children instead of hiring a nanny? Us, here reading online articles instead of buying books?
This matters because a flat sales tax makes the choice between consumption and leisure more distorted for some people than others. People who can easily substitute toward home production face a lighter burden than those who cannot. The second-best optimal commodity tax is not flat. It charges lower rates on goods that compete closely with leisure, precisely because you cannot tax leisure. The “good” condition of a uniform rate must be violated to account for the constraint you cannot remove.
Summary
The pattern is the same every time. The “leave no stone unturned” logic says: satisfy every good condition you can. But when a constraint binds, satisfying the remaining conditions can make things worse. The table below makes this explicit.
| Example | Believed “good” conditions | Reality when a constraint binds | Second-best solution |
|---|---|---|---|
| Fancy Restaurant | Dim lighting; big plate; nice food | Food is not nice | Abandon fine dining. Bright lights, normal plate, order pizza |
| Monopoly & Pollution | Break up monopoly; tax pollution | One cannot be fixed | Do nothing |
| Taxes & Public Goods | Low taxes; fund public goods | Lump-sum tax is impossible | Fund only public goods whose benefit exceeds the distortion |
| Flat Sales Tax | Uniform rate on all goods | Leisure cannot be taxed | Differentiate rates |
The Fallacy of Misplaced Valuation
You may say I am being consequentialist, and maybe that is right. We should always judge the outcome, not the individual conditions.
“Being successful is good” is our value judgement. “Waking up early, reading books will make you successful” is a factual statement. We should not confuse the logical consequences and incorrectly impose value judgements on the conditions.
The fallacy is exactly this. Because we want the outcome, we start to believe that the conditions themselves are morally good. We start to say “waking up early is a virtue” instead of “waking up early is a useful tool.” We treat the conditions as if they were the destination itself. However, the individual conditions are often neither necessary nor sufficient.
The fallacy flips the reasoning entirely. Instead of asking “What does this outcome actually require?”, you start asking “What outcome do these conditions guarantee?” The first question works backward from the goal. The second just hopes the goal somehow follows from the means.
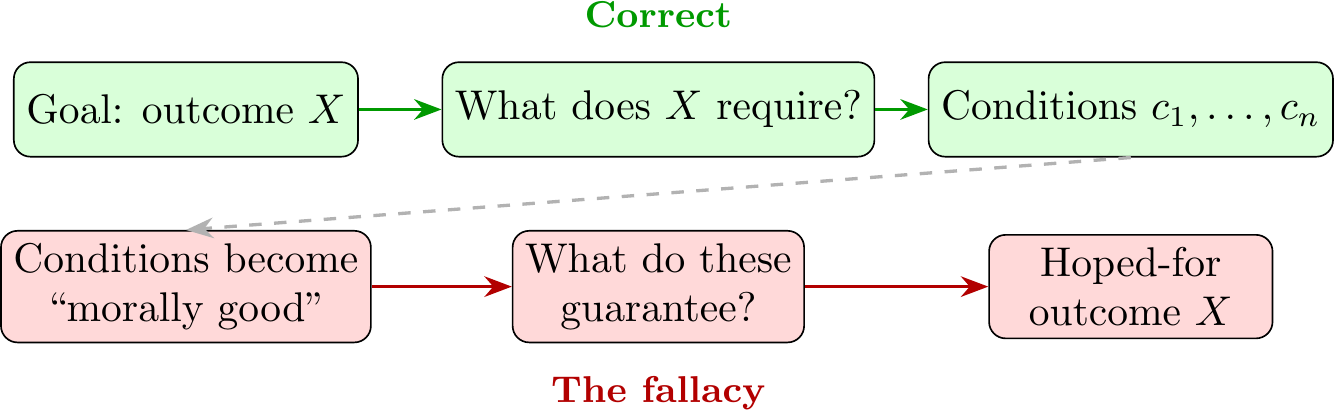 The fallacy flips the reasoning direction.
The fallacy flips the reasoning direction.
And that is why the fallacy is so hard to shake. When someone points out that a condition is not working, you do not question the condition, you question the effort. “You must not be trying hard enough.” The condition itself is never up for debate, because you have turned it from a useful observation into a moral truth.
Am I exaggerating? Not really. Even economists do this.
The First Fundamental Theorem of Welfare Economics states that a competitive market equilibrium is Pareto-efficient (good outcome), when a specific set of conditions hold simultaneously, including:
- No market powers
- Complete market
- No public goods
But then something goes wrong in the translation. Some economists, especially those who support free market, look at this list and start to treat each condition as a separate policy goal. Competition is good. Information is good. Complete markets are good. You hear it in every policy seminar: “We should liberalise this market because competition is good.” “We should disclose more information because transparency is good.”
Notice what has happened. The theorem says these conditions are jointly sufficient for efficiency. The economists hear: each condition is individually good. The theorem says they work together or not at all. They prescribes them one by one. This is exactly the “leave no stone unturned” fallacy. The reasoning goes: since satisfying all conditions produces the first-best outcome, satisfying as many as possible must be second best. It sounds reasonable. It is false.
Governments actually follow this advice. They liberalise trade while ignoring the environmental externality, because “free trade is good.” They deregulate financial markets while assuming away imperfect information, because “free markets are good.” They privatise public services while pretending the technology is convex, because “competition is good.” Each time, they are ticking off conditions from the list.
Conclusion
The right strategy depends on your constraints. No constraints? Satisfy every condition and enjoy the outcome. But constraints are usually binding, and when they are, you cannot just copy the condition list and hope for the best. The optimal solution is completely different. Sometimes, the stone you leave unturned is the one that was going to bury you.
Appendix
The Theory of the Second Best
The theory of the second best, introduced by Lipsey and Lancaster (1956), addresses a fundamental question in welfare economics: if one of the conditions required for a Pareto-optimal allocation cannot be satisfied, what is the best attainable outcome? The intuitive answer, satisfying as many of the remaining conditions as possible, is formally incorrect.
Consider a general equilibrium system characterised by $n$ first-order conditions for optimality. When all $n$ conditions hold simultaneously, the system achieves a first-best optimum. Now suppose a constraint prevents condition $i$ from being satisfied, so that the system deviates from the optimum along dimension $i$. Lipsey and Lancaster demonstrated that the new optimum (the “second best”) generally requires violating all of the remaining $n - 1$ conditions as well. The reason is that the first-order conditions are typically interdependent: they are derived from a system of simultaneous equations, so perturbing one condition alters the marginal trade-offs throughout the entire system.
The key insight is that piecemeal welfare policy, attempting to move “closer” to the first-best by satisfying individual conditions in isolation, can reduce welfare relative to doing nothing at all. The theory thus provides a formal justification for holistic, rather than incremental, policy design in second-best environments.
Proof via Lagrange Multipliers
Let the objective function be $F(x_1, x_2, \ldots, x_n)$ subject to the optimality conditions
\[g_k(x_1, x_2, \ldots, x_n) = 0, \quad k = 1, 2, \ldots, n.\]First-best. At the unconstrained optimum, all $n$ conditions hold. The Lagrangian is
\[\mathcal{L} = F(x_1, \ldots, x_n) + \sum_{k=1}^{n} \lambda_k \, g_k(x_1, \ldots, x_n),\]and the first-order conditions are
\[\frac{\partial F}{\partial x_i} + \sum_{k=1}^{n} \lambda_k \frac{\partial g_k}{\partial x_i} = 0, \quad i = 1, 2, \ldots, n. \tag{1}\]This is a system of $n$ equations in $n$ unknowns $(x_1, \ldots, x_n)$ with $n$ multipliers $(\lambda_1, \ldots, \lambda_n)$. Denote the first-best solution by $(\bar{x}_1, \ldots, \bar{x}_n)$ with multipliers $(\bar{\lambda}_1, \ldots, \bar{\lambda}_n)$.
Second-best. Now suppose a constraint forces the system to violate condition $i$: $g_i(x_1, \ldots, x_n) = c \neq 0$. The remaining $n - 1$ conditions $g_k = 0$ for $k \neq i$ are still available. The new Lagrangian is
\[\mathcal{L}' = F(x_1, \ldots, x_n) + \mu_i\,(g_i - c) + \sum_{k \neq i} \mu_k \, g_k(x_1, \ldots, x_n),\]where the constraint $g_i = c$ is now explicit. The new first-order conditions are
\[\frac{\partial F}{\partial x_j} + \mu_i \frac{\partial g_i}{\partial x_j} + \sum_{k \neq i} \mu_k \frac{\partial g_k}{\partial x_j} = 0, \quad j = 1, 2, \ldots, n. \tag{2}\]Step 1: The multipliers change. Compare (1) and (2). They share the same left-hand side $\partial F / \partial x_j$, so
\[\sum_{k=1}^{n} \lambda_k \frac{\partial g_k}{\partial x_j} = \mu_i \frac{\partial g_i}{\partial x_j} + \sum_{k \neq i} \mu_k \frac{\partial g_k}{\partial x_j}, \quad j = 1, \ldots, n.\]This is a system of $n$ linear equations in the multipliers. The first-best multipliers $(\bar{\lambda}_1, \ldots, \bar{\lambda}_n)$ satisfy the version evaluated at $(\bar{x}_1, \ldots, \bar{x}_n)$. But the second-best solution $(x_1^{\ast}, \ldots, x_n^{\ast})$ must satisfy the constraint $g_i = c$, so in general $x^{\ast} \neq \bar{x}$. Since the partial derivatives $\partial g_k / \partial x_j$ are evaluated at a different point and the constraint $g_i = c$ imposes a different feasible set, the system for the $\mu_k$ is different from the system for the $\lambda_k$. Therefore $\mu_k \neq \bar{\lambda}_k$ in general.
Step 2: The optimal values of $x$ change. For any $j$, the second-best condition (2) gives
\[\frac{\partial F}{\partial x_j} = -\sum_{k=1}^{n} \mu_k \frac{\partial g_k}{\partial x_j},\]which depends on every $\mu_k$, including $\mu_i$. Since $\mu_i \neq \bar{\lambda}_i$, the right-hand side differs from the first-best condition for every $j$, not just $j = i$. Therefore every optimal $x_j^{\ast}$ generally differs from $\bar{x}_j$.
Step 3: The remaining conditions are violated. This is the crucial step. The theorem does not merely claim that the multipliers and optimal values change. It claims that at the second-best optimum, the remaining optimality conditions $g_k(x^{\ast}) = 0$ for $k \neq i$ are themselves violated.
Suppose for contradiction that some condition $g_m(x^{\ast}) = 0$ for $m \neq i$ still holds at the second-best optimum. Then the constraint $g_m = 0$ is slack at $x^{\ast}$, which means the complementary slackness condition implies $\mu_m = 0$. But the first-best multiplier $\bar{\lambda}_m$ is generally nonzero (the constraint $g_m = 0$ binds at the first-best). So $\mu_m = 0 \neq \bar{\lambda}_m$. This change in $\mu_m$ propagates through every equation in (2), shifting the optimal values of all other variables. Since the system is interdependent, this shift will generally cause other constraints $g_k$ for $k \neq i, m$ to move away from zero as well. The only way to satisfy all $g_k(x^{\ast}) = 0$ for $k \neq i$ would be to recover the first-best solution $\bar{x}$, which violates $g_i = c$. Contradiction.
Therefore, when one optimality condition cannot be satisfied, the second-best solution generally requires violating all remaining conditions as well.
References
Lipsey, R. G., & Lancaster, K. (1956). The general theory of second best. The Review of Economic Studies, 24(1), 11–32. https://doi.org/10.2307/2296233